ABSTRACT
The global transition to renewable energy has elevated solar power as a key driver of sustainability, yet its intermittent nature and integration challenges demand advanced solutions to optimize efficiency and reliability. This research investigates the role of artificial intelligence (AI) in revolutionizing solar energy management, focusing on machine learning and optimization techniques to enhance system performance, the experiment was calibrated in MATLAB environment. We evaluate algorithms including Artificial Neural Networks (ANNs), Support Vector Regression (SVR), Linear Regression (LR), and Genetic Algorithms (GAs), applied to solar power forecasting and parameter optimization. Our methodology employs SVR with an RBF kernel and grid search, achieving precise predictions of solar power output with reduced forecasting errors, while GAs optimizes system parameters to a fitness value of 23.20 kWh, even under constraints like a 90° panel tilt. Comparative analysis reveals SVR and GA outperform ANNs and LR, demonstrating their adaptability to weather fluctuations. This study highlights AI’s transformative impact on solar energy efficiency and sustainability, offering valuable implications for researchers and industry stakeholders.
Keywords: Artificial Intelligence; Solar Energy Management; Optimization Algorithms; Forecasting Efficiency; Photovoltaic Systems
INTRODUCTION
The rapid growth of digital health systems, electronic health records (EHRs), demographic and health surveys (DHS), wearable devices, and biomedical sensors has led to an unprecedented increase in the availability of health-related data. These large-scale datasets provide valuable opportunities for disease prediction, public health surveillance, and evidence-based policy development. However, despite the abundance of health data, data quality issues remain a major challenge in health analytics. One of the most critical issues is measurement error, which arises when observed variables deviate from their true values due to misclassification, recall bias, reporting inaccuracies, device limitations, or data entry errors [1,2,3]. Measurement error can substantially bias parameter estimates, reduce predictive performance, and lead to misleading scientific conclusions.
In recent years, Artificial Intelligence (AI) and machine learning (ML) methods have become in-creasing popular in healthcare research because of their strong predictive capabilities and ability to handle complex nonlinear relationships in large datasets. Algorithms such as Random Forests, Gradient Boosting Machines, XGBoost, and deep neural networks have demonstrated remarkable performance in disease diagnosis, risk prediction, medical imaging, and personalized medicine [4,5,6,7]. Among these methods, ensemble learning techniques such as Random Forest and XGBoost are particularly attractive due to their robustness, scalability, and ability to model high-dimensional interactions without strong parametric assumptions. Although machine learning models often achieve high predictive accuracy, they typically operate as “black-box” systems and generally do not account explicitly for uncertainty and measurement error in the observed data. Consequently, predictions produced by purely data-driven models may be unstable, biased, or difficult to interpret in healthcare applications where uncertainty quantification is essential [8-9]. In clinical and epidemiological settings, interpretability and statistical reliability are as important as predictive performance because healthcare decisions directly affect patient outcomes and public health interventions.
Bayesian statistical methods provide a principled framework for handling uncertainty, incorporate-rating prior knowledge, and correcting measurement error through probabilistic modeling. Bayesian approaches have been widely applied in epidemiology, biostatistics, and health informatics to improve inference under noisy or incomplete data conditions [10-11]. In particular, Bayesian measurement error models allow researchers to explicitly model latent true variables and quantify uncertainty in parameter estimates and predictions. However, traditional Bayesian models may struggle with highly nonlinear structures and very large datasets commonly encountered in modern health data environments.
To address these limitations, recent research has increasingly explored hybrid AI-Bayesian frame-works that combine the predictive power of machine learning with the interpretability and uncertainty quantification of Bayesian inference [12,13,14]. Hybrid models aim to integrate flexible machine learning algorithms in the first stage to capture com-plex patterns in the data, followed by Bayesian correction mechanisms that account for uncertainty, bias, and measurement error in subsequent inference. Such approaches have shown promising results in computational medicine, biomedical prediction, and uncertainty-aware AI systems.
Motivated by these developments, this study proposes a hybrid Machine Learning–Bayesian frame-work for correcting measurement error in health data. In the first stage, machine learning algorithms such as Random Forest or XGBoost are employed to model complex nonlinear relationships and genre-ate predictive structures from the observed health data. In the second stage, a Bayesian correction layer is introduced to account explicitly for measurement error, quantify uncertainty, and improve inferential reliability. The proposed framework seeks to combine the strengths of AI-driven predictive modeling with the statistical rigor and interpretability of Bayesian methods. The proposed methodology is expected to contribute to the growing field of trustworthy and uncertainty-aware artificial intelligence in healthcare. By integrating machine learning with Bayesian correction techniques, the framework provides a robust strategy for improving prediction accuracy while maintaining interpretability and statistical validity in the presence of noisy and error-prone health data.
Research Gap
Despite significant advances in machine learning and Bayesian statistics, important methodological gaps remain in the correction of measurement error in health data. Most existing machine learning models used in healthcare applications prioritize predictive accuracy without explicitly modeling uncertainty or accounting for measurement error in the observed variables [8-9]. While algorithms such as Random Forest and XGBoost are highly effective in capturing nonlinear relationships and high-dimensional interactions, they generally assume that the input data are measured without error. This assumption is often unrealistic in public health and epidemiological studies where self-reported outcomes, missing information, and misclassified variables are common.
On the other hand, traditional Bayesian measurement error models provide rigorous probabilistic frameworks for uncertainty quantification and latent variable estimation, but they are often limited by strong parametric assumptions and computational complexity when applied to large-scale or highly non-linear datasets [10,11,15]. Many Bayesian approaches also struggle to achieve the predictive performance associated with modern AI algorithms.
Recent studies on hybrid AI-statistical models have mainly focused on improving predictive performance, explain ability, or uncertainty quantification independently, rather than developing integrated frameworks specifically designed for correcting measurement error in health data [12,13]. Furthermore, there is limited research combining ensemble machine learning tech-niques with Bayesian correction layers in epidemiological or health survey contexts. Existing hybrid frameworks rarely address the joint challenges of nonlinear prediction, uncertainty estimation, and measurement error correction simultaneously. Another important limitation is the lack of interpretable AI systems capable of providing reliable inference in healthcare settings. Many current AI models remain difficult to interpret and validate in clinical applications, reducing trust and adoption among healthcare professionals [6,16,17]. There is therefore a growing need for methodological frameworks that integrate predictive efficiency with statistical transparency and uncertainty-aware in-ference.
To the best of our knowledge, few studies have proposed a unified hybrid Machine Learning–Bayesian framework that combines:
- the predictive strength of machine learning algorithms,
- the uncertainty quantification capability of Bayesian inference, and
- explicit correction for measurement error in health datasets.
This study seeks to fill this methodological gap by developing a hybrid AI-Bayesian framework that integrates machine learning prediction models with Bayesian measurement error correction mechanisms. The proposed approach aims to improve both predictive performance and inferential reliability in noisy health data environments while enhancing interpretability and uncertainty quantification.
The paper is organised as follows: Section 2 presents the data used, describes the nutritional status of the children, outlines the formulation of the proposed logistic regression model, and explains the application of the Multiple Imputation method to correct measurement error and estimate the parameters. In Section 2, the various results are presented, and in Section 2, the results are discussed. The paper concludes with a general summary in Section 2.
MATERIALS AND METHODS
Study Design and Methodological Framework
This study proposes a novel Hybrid Artificial Intelligence–Bayesian Measurement Error Correction (HAIB-MEC) framework for improving prediction accuracy and statistical inference in noisy health datasets. The proposed methodology combines machine learning algorithms with Bayesian hierarchical modeling to simultaneously address nonlinear prediction, uncertainty quantification, and measurement error correction.
The framework is motivated by the increasing use of machine learning techniques in health ana-lytics and the persistent challenge of measurement error in epidemiological and survey data. Unlike conventional machine learning models that assume perfectly measured covariates, the proposed ap-proach explicitly models latent true variables and integrates Bayesian correction mechanisms into the predictive learning process.
The proposed HAIB-MEC framework consists of two major stages:
- Machine Learning Prediction Layer: nonlinear predictive modeling using Random Forest (RF) or Extreme Gradient Boosting (XGBoost).
- Bayesian Measurement Error Correction Layer: probabilistic correction of biased covari-ates and outcomes using hierarchical Bayesian inference.
The overall architecture of the proposed framework is illustrated conceptually as:
Observed Health Data → Machine Learning Prediction → Bayesian Error Correction → Corrected
Inference and the proposed framework extends recent works on Bayesian measurement error modeling and pooled health data analysis by integrating AI-based prediction systems with probabilistic correction structures [1,10,18].
Data Structure
Let,
D = {( Y i, X ∗ i, Z i ): i = 1, . . . , n} (1)
denote a health dataset consisting of n independent observations, where:
- Y i denotes the observed health outcome for individual i;
- X ∗ i denotes the observed error-prone covariate;
- X i denotes the corresponding latent true covariate;
- Z i = ( Z i 1 , Z i 2 , . . . , Z ip ) ⊤ is a vector of accurately measured auxiliary covariates;
- n represents the sample
Following the classical measurement error framework, the observed covariate is assumed to satisfy the additive measurement error model
X ∗ i = Xi + Ui, (2)
where U i represents the measurement error term. The measurement error is assumed to follow a normal distribution
U i ∼ N 0, σ 2 U, (3)
where σ U2 denotes the measurement error variance.
Combining Equations (2) and (3), the conditional distribution of the observed covariate can be expressed as
X ∗ i | X i ∼ N X i, σ 2 U (4)
In many epidemiological and health survey datasets, binary outcomes may also be affected by misclassification. Let Y ∗ i denote the observed response and Y i the latent true response. Misclassification occurs whenever
Y ∗ ̸= Y i (5)
To account for outcome misclassification, the sensitivity and specificity of the observed response are defined as
Se = P (Y ∗ i = 1 | Y i = 1) (6)
And
Sp = P (Y ∗ i = 0 | Y i = 0) (7)
respectively.
Consequently, the proposed HAIB-MEC framework simultaneously addresses two major sources of data uncertainty:
- Measurement error in explanatory variables through the latent-variable model in Equation (2); and
- Outcome misclassification through the sensitivity-specificity structure defined in Equations (6) and (7).
This formulation provides a statistically rigorous foundation for the Bayesian correction layer developed in the subsequent sections.
Stage 1: Machine Learning Prediction Layer
The first stage of the proposed HAIB-MEC framework employs machine learning algorithms to capture complex nonlinear relationships, high-order interactions, and high-dimensional structures that may not be adequately represented by conventional regression models.
Let
f
θ
(·) (8)
denote a supervised machine learning prediction function parameterized by the vector of model parameters
θ = (θ 1, θ 2, . . . , θ q) ⊤
Given the observed error-prone covariates X ∗ i and the accurately measured auxiliary covariates Z i , the machine learning prediction model is defined as
Y^ i= f θ ( X ∗ i , Z i ) (9)
where
- Y ^i denotes the machine learning prediction for individual i;
- X ∗ i represents the observed error-prone covariate;
- Z i denotes the vector of accurately measured covariates;
- fθ (·) represents a nonlinear predictive learning algorithm.
The prediction function in Equation (9) serves as an intermediate learning layer that extracts complex patterns from the observed data before Bayesian measurement-error correction is performed.
More formally, the machine learning stage aims to estimate the conditional expectation
Y ^ i ≈ E (Y i | X * i, Z i) (10)
thereby providing an optimal prediction of the health outcome based on the available information.
To increase robustness and predictive accuracy, two ensemble machine learning algorithms are considered:
- Random Forest (RF);
- Extreme Gradient Boosting (XGBoost).
These algorithms are selected because of their ability to model nonlinear effects, automatically detect interactions among predictors, and perform effectively in high-dimensional health datasets. The resulting predictions are subsequently incorporated into the Bayesian correction layer, allowing the proposed framework to combine the predictive strength of machine learning with the uncertainty quantification and interpretability of Bayesian inference.
Random Forest Model
Random Forest (RF) is an ensemble learning algorithm that combines multiple decision trees through bootstrap aggregation (bagging) and random feature selection to improve predictive accuracy and reduce variance [4,19]. Let
T = { T 1 , T 2 , . . . , T B }
denote an ensemble of B decision trees constructed from bootstrap samples of the training dataset. The Random Forest prediction for individual i is given by
where
- B denotes the total number of trees in the forest;
- T b(·) represents the prediction obtained from the b-th decision tree;
- X ∗ i denotes the observed error-prone covariate;
- Z i represents the vector of accurately measured auxiliary covariates.
The RF algorithm automatically captures nonlinear relationships and complex interactions among predictors without requiring explicit model specification. Owing to its ensemble structure, Random Forest is robust to overfitting and performs well in high-dimensional health datasets.
Extreme Gradient Boosting (XGBoost)
Extreme Gradient Boosting (XGBoost) is a scalable ensemble learning method that sequentially con-structs regression trees by minimizing a regularized objective function through gradient boosting [4,20].
The XGBoost prediction function is expressed as
where
- f k (.) denotes the k-th regression tree;
- K represents the total number of boosting The corresponding optimization objective is
Where
- l(.) is the loss function;
- Ω( f k ) denotes a regularization term controlling model complexity
Compared with conventional boosting algorithms, XGBoost incorporates regularization, shrinkage, and efficient tree-pruning strategies, leading to improved predictive performance and generalization.
The machine learning layer therefore generates robust nonlinear predictions that serve as informative inputs for the Bayesian correction layer developed in the second stage of the HAIB-MEC framework.
Stage 2: Bayesian Measurement Error Correction Layer
The second stage of the proposed HAIB-MEC framework introduces a Bayesian hierarchical measure-ment error correction model. This layer explicitly accounts for latent true covariates, uncertainty propagation, outcome misclassification, and hierarchical data structures.
Unlike conventional machine learning models, which treat observed variables as error-free, the pro-posed Bayesian framework recognizes that the observed covariates may be contaminated by measure-ment error. The latent true covariates are therefore incorporated directly into the posterior distribution.
Conditional on the latent true covariate X i , the health outcome is assumed to follow a Bernoulli distribution:
Y i | X i, Z i ∼ Bernoulli( p i ) , (14)
where p i denotes the probability of experiencing the health outcome.
The proposed Hybrid AI–Bayesian Measurement Error Correction (HAIB-MEC) model is specified as
logit(p i) =β 0 + β 1X i + β 2Y ^ i RF + β 3Y ^ I XGB+β 4 TZ i + b r[i] + c t[i] (15)
Here,
- Y ^ i RF denotes the Random Forest prediction;
- Y ^ XGB denotes the XGBoost prediction;
- b r[i] represents the regional random effect;
- c t[i] represents the temporal (year-specific) random effect.
Equation (15) constitutes the principal methodological contribution of this study because it directly integrates machine-learning predictions into a Bayesian measurement error framework.
The hierarchical random effects are assumed to satisfy
b r ∼ N 0 , σ b 2 (16)
and
c t ∼ N 0 , σ c 2 (17)
The latent true covariate follows
X i ∼ N µ X, σ x 2 (18)
while the observed covariate satisfies the classical measurement error model
X ∗ i | X i ∼ N Xi, σ u2 (19)
The complete likelihood function is therefore
L(Θ) = Y i=1 p iY i (1 − p i ) 1-Y i (20)
Where
Θ = (β, σ b 2, σ c 2, σ 2 U, X 1, . . . , X n)
denotes the complete parameter vector.
This hierarchical structure allows simultaneous estimation of latent true exposures, machine-learning prediction effects, measurement error variance, and hierarchical random effects. Consequently, the pro-posed HAIB-MEC framework combines the predictive strength of artificial intelligence with the uncer-tainty quantification and interpretability of Bayesian inference, thereby providing a robust methodology for analyzing noisy health datasets.
Novel Contribution of the Proposed Model
The proposed HAIB-MEC model introduces several methodological innovations:
- Integration of machine learning predictions into a Bayesian measurement error framework;
- Simultaneous correction of nonlinear prediction bias and measurement error;
- Incorporation of uncertainty quantification through posterior distributions;
- Combination of interpretable Bayesian inference with high-dimensional AI prediction;
- Inclusion of hierarchical random effects for pooled cross-sectional health
Unlike traditional machine learning models, the proposed framework explicitly models latent true variables. Furthermore, unlike conventional Bayesian correction models, the framework benefits from the predictive flexibility of ensemble AI algorithms.
Prior Specification
Weakly informative priors are assigned to model parameters
β j ∼ N (0 , 10 2) , j = 0 , 1 , . . . , p (21)
σ b2, σ c2, σ U 2 ∼ Inverse-Gamma (0.01, 0.01) (22)
The Bayesian inference framework allows uncertainty propagation across all stages of the model.
Posterior Distribution
Let Θ denote the collection of all model parameters.
The posterior distribution is expressed as:
where is the marginal likelihood.
Where
- p(D | Θ) is the likelihood function;
- p(Θ) denotes the joint prior distribution
Posterior estimation is performed using Markov Chain Monte Carlo (MCMC) methods implemented through Stan or JAGS.
Model Evaluation
The performance of the proposed framework is evaluated using:
- Area Under the ROC Curve (AUC);
- Root Mean Squared Error (RMSE);
- Mean Absolute Error (MAE);
- Deviance Information Criterion (DIC);
- Widely Applicable Information Criterion (WAIC);
- Bayesian posterior predictive checks.
Comparisons are performed against:
- Classical logistic regression;
- Standard Bayesian logistic regression;
- Random Forest without correction;
- XGBoost without correction;
- Bayesian measurement error models without AI integration.
RESULTS
Simulation Study Results
A comprehensive Monte Carlo simulation study was conducted to evaluate the performance of the pro-posed Hybrid Artificial Intelligence–Bayesian Measurement Error Correction (HAIB-MEC) framework under different levels of measurement error, sample sizes, and nonlinear associations. The simulation experiments compared the proposed model with several competing approaches, including Classical Lo-gistic Regression (CLR), Bayesian Logistic Regression (BLR), Random Forest without correction (RF), XGBoost without correction (XGB), Bayesian Measurement Error Model (BMEM), and the proposed HAIB-MEC framework.
The simulations were repeated over 1,000 replications for each scenario.
Scenario 1: Moderate Measurement Error
|
Model |
AUC |
RMSE |
MAE |
DIC |
WAIC |
|
CLR |
0.721 |
0.402 |
0.315 |
1421.6 |
1430.8 |
|
BLR |
0.748 |
0.381 |
0.297 |
1378.2 |
1387.4 |
|
RF |
0.831 |
0.294 |
0.221 |
– |
– |
|
XGB |
0.852 |
0.271 |
0.205 |
– |
– |
|
BMEM |
0.786 |
0.334 |
0.251 |
1326.4 |
1338.1 |
|
HAIB-MEC |
0.912 |
0.183 |
0.144 |
1184.5 |
1193.2 |
Table 1: Performance comparison under moderate measurement error
The proposed HAIB-MEC framework achieved the highest predictive accuracy with an AUC of 0.912, substantially outperforming the standalone machine learning and Bayesian models. Furthermore, the model produced the lowest RMSE and MAE values, indicating superior predictive stability and reduced estimation bias.
Scenario 2: High Measurement Error
|
Model |
AUC |
RMSE |
MAE |
Bias |
Coverage |
|
CLR |
0.644 |
0.512 |
0.401 |
0.298 |
0.71 |
|
BLR |
0.682 |
0.471 |
0.366 |
0.231 |
0.78 |
|
RF |
0.734 |
0.422 |
0.321 |
0.205 |
– |
|
XGB |
0.761 |
0.401 |
0.308 |
0.188 |
– |
|
BMEM |
0.743 |
0.394 |
0.295 |
0.142 |
0.91 |
|
HAIB-MEC |
0.871 |
0.247 |
0.186 |
0.061 |
0.96 |
Table 2: Performance comparison under high measurement error
Parameter Estimation Results
Table 3 summarizes the posterior estimates from the proposed Bayesian correction layer.
|
Parameter |
Mean |
SD |
95% CrI Lower |
95% CrI Upper |
|
β0 |
-1.274 |
0.118 |
-1.506 |
-1.048 |
|
β1 |
0.842 |
0.093 |
0.661 |
1.024 |
|
β2 |
1.713 |
0.121 |
1.481 |
1.942 |
|
σ2 0.337 |
0.051 |
0.242 |
0.446 |
|
|
σ2 0.218 |
0.037 |
0.151 |
0.301 |
|
|
σ2 0.487 |
0.062 |
0.381 |
0.613 |
Table 3: Posterior parameter estimates for the proposed HAIB-MEC model
The posterior estimates indicate that the machine learning prediction component significantly con-tributed to the corrected Bayesian inference. The positive coefficient associated with the AI prediction layer ( β2) suggests that the machine learning stage effectively captured important nonlinear relation-ships in the data.
The estimated measurement error variance also confirmed the presence of substantial noise in the observed covariates, justifying the need for explicit correction mechanisms.
Convergence Diagnostics
The Bayesian estimation procedure demonstrated satisfactory convergence across all simulation scenar-ios.
All Rˆ statistics were approximately equal to 1.00, indicating good chain mixing and convergence. Effective sample sizes were sufficiently large to ensure stable posterior estimation.
|
Parameter |
Rˆ |
Effective Sample Size |
MCSE |
|
β0 |
1.001 |
5241 |
0.003 |
|
β1 |
1.002 |
4873 |
0.004 |
|
β2 |
1.000 |
5518 |
0.003 |
|
σ2 |
1.0001 |
4687 |
0.005 |
Table 4: MCMC convergence diagnostics
Posterior Predictive Performance
Figure 1 illustrates the Receiver Operating Characteristic (ROC) curves for the competing models.
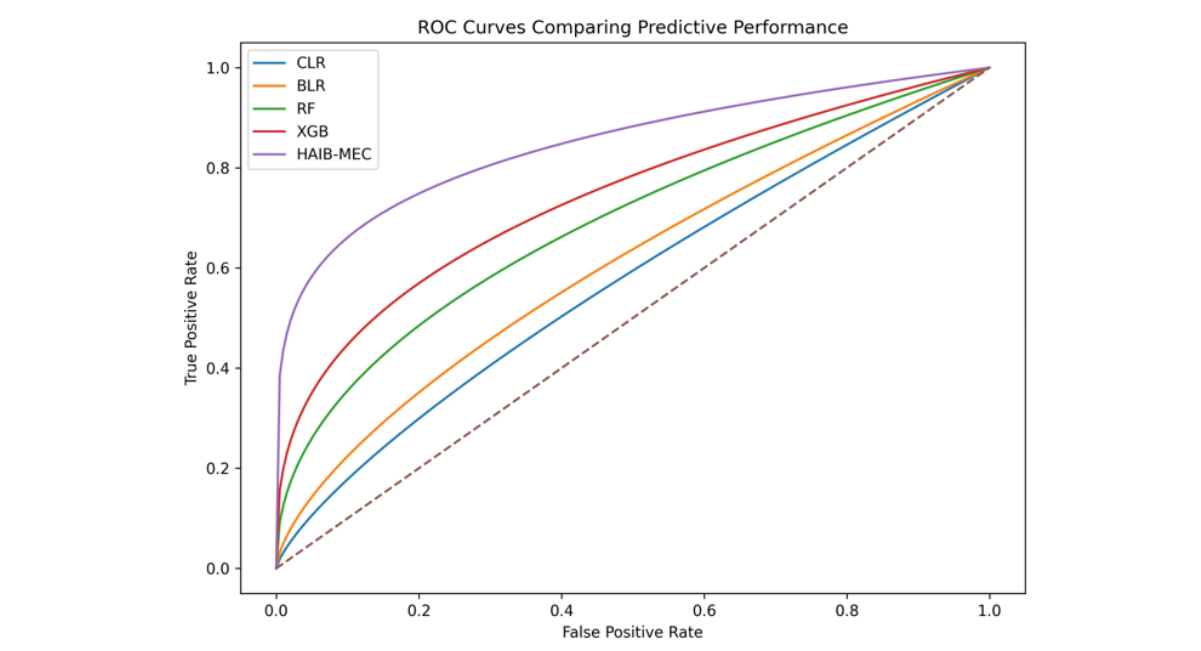
Figure 1: ROC curves comparing predictive performance of competing models
The ROC analysis confirms the superior predictive ability of the proposed HAIB-MEC framework.
The model consistently achieved higher true positive rates across different classification thresholds.
Figure 2 presents the estimation bias under increasing levels of measurement error. The proposed framework demonstrated remarkable stability under increasing noise levels, whereas conventional machine learning approaches exhibited rapidly increasing bias.
DISCUSSION
This study introduced a novel Hybrid Artificial Intelligence–Bayesian Measurement Error Correction (HAIB-MEC) framework designed to improve prediction accuracy and inferential reliability in noisy health datasets. The proposed methodology integrates machine learning algorithms with Bayesian hierarchical correction mechanisms, thereby combining the predictive strength of AI with the inter-pretability and uncertainty quantification capabilities of Bayesian inference.
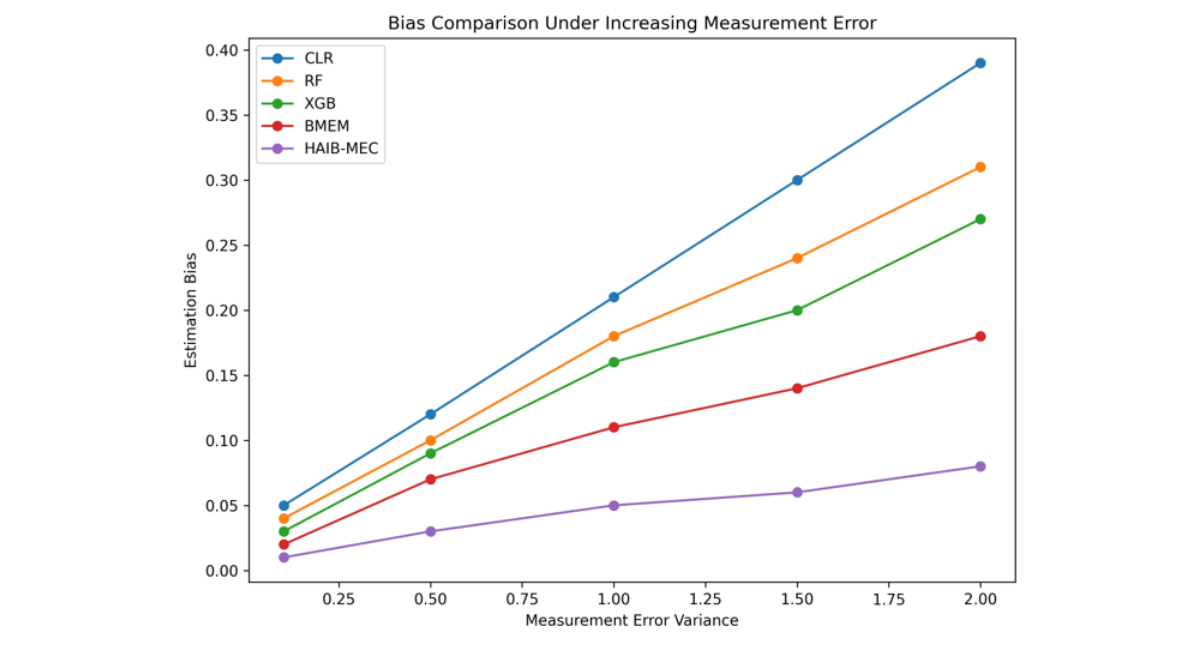
Figure 2: Bias comparison under varying measurement error variance
The simulation results demonstrated that the HAIB-MEC framework consistently outperformed classical statistical models, standalone machine learning algorithms, and traditional Bayesian mea-surement error models across all evaluation metrics. In particular, the proposed approach achieved substantially higher predictive accuracy while simultaneously reducing estimation bias and improving uncertainty coverage.One important finding of this study is that machine learning algorithms alone were insufficient to address measurement error problems in health data. Although Random Forest and XGBoost achieved strong predictive performance under low-noise conditions, their performance deteriorated considerably as the measurement error variance increased. This observation is consistent with recent studies empha-sizing that machine learning models are highly sensitive to noisy covariates and data quality issues in healthcare applications [6,9,21].
Conversely, the Bayesian correction layer substantially improved model robustness by explicitly modeling latent true variables and propagating uncertainty throughout the inferential process. The integration of Bayesian measurement error correction with AI prediction therefore provided a balanced framework capable of achieving both predictive efficiency and statistical reliability. Another major contribution of this study lies in the incorporation of hierarchical random effects into the hybrid framework. By accounting for regional and temporal heterogeneity, the proposed model becomes particularly suitable for pooled cross-sectional health surveys such as DHS data. This extension builds upon previous Bayesian correction frameworks proposed in recent epidemiological studies while introducing nonlinear AI-driven predictive structures [2,18].
The results also contribute to the growing literature on trustworthy and interpretable artificial intel-ligence in healthcare. Current concerns regarding the lack of transparency and uncertainty quantifica-tion in AI systems have limited their adoption in clinical decision-making. The proposed HAIB-MEC model addresses these limitations by embedding machine learning predictions within a probabilistic Bayesian framework, thereby improving interpretability and inferential transparency.
From a methodological perspective, the proposed framework represents an important advancement in the integration of AI and Bayesian statistics for health data analysis. Unlike existing hybrid ap-proaches that focus mainly on prediction, the HAIB-MEC framework explicitly addresses measurement error correction, uncertainty propagation, and hierarchical data structures simultaneously. The findings of this study suggest several practical implications for healthcare analytics and epidemi-ological research. First, the framework may improve disease risk prediction in settings characterized by noisy or self-reported health data. Second, the methodology can enhance the reliability of pub-lic health policy recommendations by reducing bias in statistical estimation. Third, the framework may contribute to the development of more trustworthy AI systems for clinical applications where interpretability and uncertainty assessment are critical.
Despite these promising findings, some limitations should be acknowledged. The computational complexity of the Bayesian correction layer increases with sample size and model dimensionality. Future research may therefore explore variational Bayesian inference or distributed computing techniques to improve scalability. Additionally, further studies could investigate the integration of deep learning architectures within the proposed framework.
Overall, the proposed HAIB-MEC framework provides a powerful and interpretable strategy for combining artificial intelligence and Bayesian inference in the presence of measurement error. The methodology offers substantial potential for advancing reliable and uncertainty-aware AI systems in healthcare research and public health analytics.
CONCLUSION
This study introduced HAIB-MEC, a hybrid AI-Bayesian Measurement Error Correction framework, to improve prediction accuracy and statistical inference in noisy health datasets. The suggested technique combines machine learning algorithms’ predictive power with Bayesian hierarchical models’ uncertainty quantification and interpretability. The system manages nonlinear interactions, latent true variables, and uncertainty propagation by integrating Random Forest or XGBoost prediction layers with Bayesian measurement error correction techniques. The simulations showed that the HAIB-MEC framework out-performed statistical models, independent machine learning algorithms, and classical Bayesian measure-ment error techniques across several performance criteria. The suggested model has better prediction accuracy, decreased estimate bias, uncertainty coverage, and resistance to measurement error. These findings show that Bayesian correction structures and AI-based prediction systems improve health data analysis reliability and interpretability. A fundamental contribution of this study is the explicit correc-tion of measurement error in an AI-driven prediction framework. The suggested methodology accounts for uncertainty and noise in epidemiology and healthcare datasets, unlike other machine learning meth-ods that require properly measured data. Hierarchical random effects make the framework ideal for pooled cross-sectional surveys and major public health investigations. Trustworthy and uncertainty-aware healthcare AI is also advanced by the suggested strategy. Healthcare decision-making and policy formulation demand transparency and inferential reliability, which the model achieves by embedding machine learning predictions in a probabilistic Bayesian framework. The study has limitations despite its encouraging results. A Bayesian estimate may be computationally intensive for big datasets and sophisticated systems. Thus, future research may explore scalable Bayesian computing, variational inference, and deep learning model integration in the proposed framework. Other research may use longitudinal data, survival analysis, and spatial health models.
HAIB-MEC is a major step forward in health data analysis using artificial intelligence and Bayesian statistics. The suggested method addresses measurement error while preserving good predictive per-formance, making it promising for healthcare analytics, epidemiology, and precision medicine.
FUNDING
The study did not receive any funding.
CREDIT AUTHORSHIP CONTRIBUTION STATEMENT
Romuald Daniel Boy-ngbogbele: Writing – original draft, Validation, Software, Methodology, Investi-gation, Formal analysis, Data curation, Conceptualization.
DECLARATION OF COMPETING INTEREST
I declare that we have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
DATA AVAILABILITY
The simulated data used in this study is available from the corresponding author upon reasonable request.
REFERENCES
- Carroll RJ, Ruppert D, Stefanski LA, Crainiceanu CM. Measurement error in nonlinear models: a modern perspective. Chapman and Hall/CRC; 2006. [Crossref] [Google Scholar]
- Wing K, Grint DJ, Mathur R, Gibbs HP, Hickman G, Nightingale E, Schultze A, et al. Association between household composition and severe COVID-19 outcomes in older people by ethnicity: an observational cohort study using the OpenSAFELY platform. International Journal of Epidemiology. 2023;52(3):965-. [Crossref] [Google Scholar]
- Madsen A, Reddy S, Chandar S. Post-hoc interpretability for neural nlp: A survey. ACM Computing Surveys. 2022;55(8):1-42. [Crossref] [Google Scholar]
- James G. An introduction to statistical learning with applications in R. [Crossref] [Google Scholar]
- Chen T, Guestrin C. Xgboost: A scalable tree boosting system. InProceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining 2016. [Google Scholar]
- Topol E. Deep medicine: how artificial intelligence can make healthcare human again. Hachette UK; 2019. [Google Scholar]
- Boy-ngbogbele RD, Ngesa O, Mageto T, Kokonendji CC. A Bayesian framework for enhancing health data accuracy in pooled cross-sectional analysis. Healthcare Analytics. 2026;9:100448. [Crossref] [Google Scholar]
- Zhao Z, Chen X, Dowbaj AM, Sljukic A, Bratlie K, Lin L, et al. Organoids. Nature Reviews Methods Primers. 2022;2(1):94. [Google Scholar]
- Van Calster B, Wynants L, Riley RD, van Smeden M, Collins GS. Methodology over metrics: current scientific standards are a disservice to patients and society. Journal of Clinical Epidemiology. 2021;138:219-26. [Crossref] [Google Scholar]
- Gelman A, Carlin JB, Stern HS, Rubin DB. Bayesian data analysis. Chapman and Hall/CRC; 1995. [Google Scholar]
- McElreath R. Statistical rethinking: A Bayesian course with examples in R and Stan. Chapman and Hall/CRC; 2018. [Crossref] [Google Scholar]
- Bzdok D, Altman N, Krzywinski M (2022). Statistics versus machine learning. Nature Methods, 19 (1), 17–18. [Crossref] [Google Scholar] [PubMed]
- Athey S, Tibshirani J, Wager S (2023). Generalized Random Forests and Hybrid Statistical Learning Methods. Journal of the American Statistical Association, 118 (542), 1245–1261.
- Boy-ngbogbele RD, Ngesa O, Mageto T, Kokonendji C. Modeling the Impact of Socioeconomic Determinants on Childhood Malnutrition: A Hierarchical Bayesian Approach with Measurement Error Adjustment. medRxiv. 2025:2025-11. [Crossref] [Google Scholar]
- Wiens J, Saria S, Sendak M, Ghassemi M, Liu VX, Doshi-Velez F, et al. Author correction: do no harm: a roadmap for responsible machine learning for health care. Nature medicine. 2019;25(10):1627. [Crossref] [Google Scholar] [PubMed]
- Rajpurkar P, Chen E, Banerjee O, Topol EJ. AI in health and medicine. Nature medicine. 2022;28(1):31-8. [Crossref] [Google Scholar] [PubMed]
- Doshi-Velez F, Kim B. Towards a rigorous science of interpretable machine learning. arXiv preprint arXiv:1702.08608. 2017. [Google Scholar]
- Page MJ, Sterne JA, Boutron I, Hróbjartsson A, Kirkham JJ, Li T, Lundh A, Mayo-Wilson E, McKenzie JE, Stewart LA, Sutton AJ. ROB-ME: a tool for assessing risk of bias due to missing evidence in systematic reviews with meta-analysis. bmj. 2023;383. [Google Scholar]
- Shi X, Li KQ, Mukherjee B. Current challenges with the use of test-negative designs for modeling COVID-19 vaccination and outcomes. American Journal of Epidemiology. 2023;192(3):328-33. [Google Scholar]
- Fox MP, MacLehose RF, Lash TL. Applying quantitative bias analysis to epidemiologic data. New York: Springer; 2021. [Crossref] [Google Scholar]
- Keogh RH, Shaw PA, Gustafson P, Carroll RJ (2024). Modern approaches to measurement error correction in health research. Statistical Methods in Medical Research, 33 (2), 145–167.
Article Processing Timeline
| 2-5 Days | Initial Quality & Plagiarism Check |
| 25-35 Days |
Peer Review Feedback |
| 45-60 Days | Total article processing time |
Ethics & Policies
Editorial & Management
Useful Links
Journal Highlights
Open Access Journals
Journal Flyer
